
Audio Analytics with OpenAI: How Whisper Transforms Audio into Insight | marketing analytics company

Have you ever felt overwhelmed by the flood of audio content that comes out every day? Podcasts are piling up, meeting recordings are sitting in your inbox, and interesting lectures you missed are stuck in video files. The amount of information you hear through words can be paralyzing, leaving you longing for a way to capture the essence of it without getting lost in the details. Well, there is a way. OpenAI’s Whisper instantly transcribes any audio file with pinpoint accuracy and creates a concise summary of an hour’s worth of audio files so you can easily extract key points.
Whisper: An open AI model for text-to-speech
Whisper’s strengths lie in its advanced neural network architecture and access to large datasets of diverse audio and text. This translates into several key features:
- Multilingual function: Break down language barriers and analyze content in a variety of languages, from everyday conversation to technical jargon.
- Transcription Accuracy: It is ideal for research, legal proceedings and accessibility purposes as it minimizes errors and ensures near-perfect records.
- Domain adaptability: Accurately record lectures, interviews, and even technical recordings with high fidelity.
How it works
Whisper leverages the Transformer architecture, a neural network with an attention mechanism for learning relationships between input and output sequences. It consists of two main components: encoder and decoder.
The encoder processes the audio input, converts it into 30-second chunks, converts them to a Log-Mel spectrogram, and encodes them into hidden vectors.
The decoder takes these vectors and predicts the corresponding text output. Special tokens are used for a variety of tasks, such as language identification, phrase-level timestamps, multilingual speech transcription, and English speech translation.
why is it better
Whisper has several advantages over existing text-to-speech (TTS) systems.
- We were trained on a diverse dataset consisting of 680,000 hours of audio and text covering a variety of domains, accents, background noise, and technical language.
- Handle multiple languages and tasks with a single model, automatically identifying the language of the input audio and switching tasks accordingly.
- It demonstrates high accuracy and performance in speech recognition and outperforms specialized models on a variety of data sets.
Sample application (audio-to-text summarization using Whisper and BART)
We implemented a Whisper model to transcribe and summarize video/audio content using OpenAI’s BART summary model. This feature is very useful for recording meeting notes, call recordings, or video/audio, saving you a lot of time.
draw close:
- Develop a UI using Streamlit by providing a YouTube URL as input.
- Extract audio from video file using Pytube.
- Convert audio to text using the Whisper model.
- Split text into chunks using the BartTokenizer/TextDavinci model.
- We use the Bart model to summarize chunks and produce output.
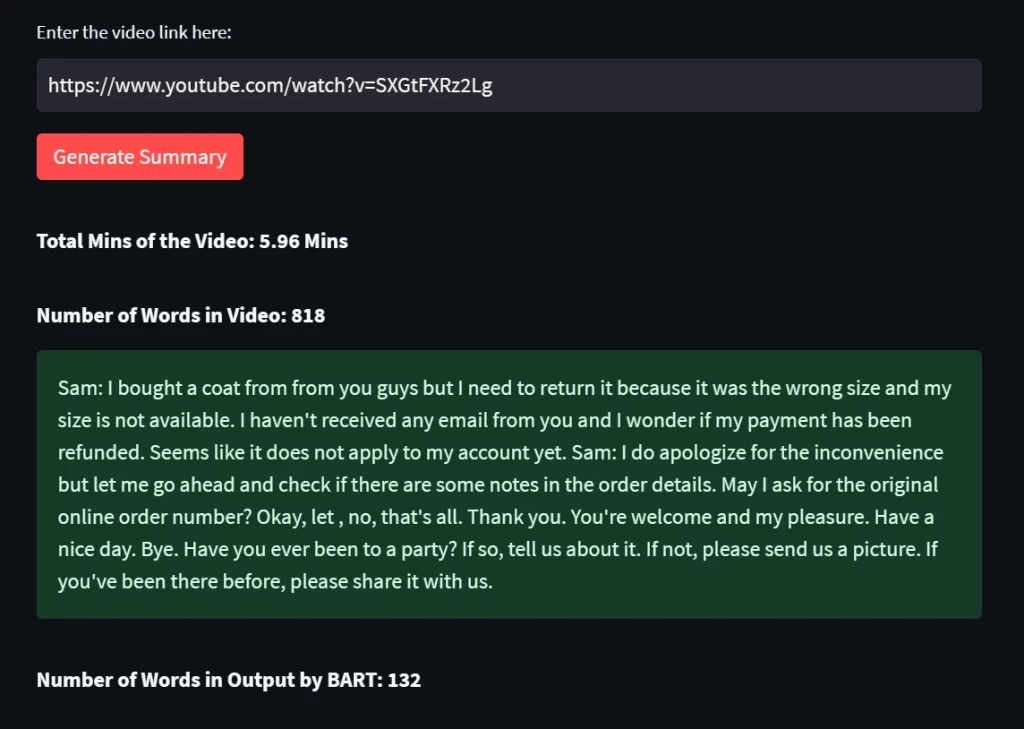
Sample output:
1. a)
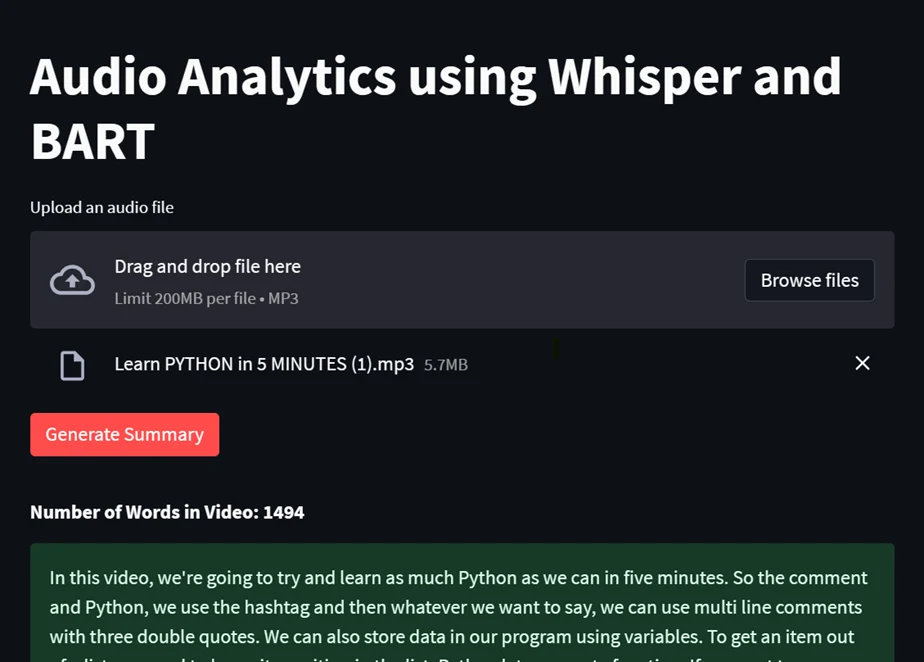
1. B)
The Limits of a Whisper
Whisper is a powerful audio analysis solution, but it has some limitations.
- Works better on GPU systems.
- Prolonged audio silence can cause hallucinations and confuse the decoder.
- You are limited to processing 30 seconds of audio at a time.
Use cases across industries
Whisper’s applications extend beyond just transcription. Here are some examples:
- Transcription Services: Companies can leverage Whisper’s API to serve a variety of customers by providing fast, accurate, and cost-effective transcription in multiple languages.
- Language Learning: Practice improving your intonation by comparing your speech to Whisper’s perfect output.
- customer service: We analyze customer calls in real time, understand customer needs, and improve service based on feedback.
- market research: Collect real-time feedback from customer interviews, focus groups, and social media mentions to extract valuable insights to inform your product development and marketing strategy.
- Voice-based search: Develop an innovative voice-activated search engine that understands and responds to users in multiple languages.
conclusion:
OpenAI’s Whisper represents a significant leap forward in audio understanding, helping individuals and businesses unlock the wealth of information contained in speech. With unparalleled accuracy, multilingual capabilities, and a wide range of applications, Whisper can reimagine the way we interact with and extract value from audio content.