

This post originally appeared in ZeMing M. Gao’s post. Website, republished with permission from the author. Read the full story here.
Is Bitcoin’s Merkle tree a binary search tree?
Dr. Craig Wright says Bitcoin’s Merkle tree is a binary search tree. BTC developers disagree and question his credentials. BTC’s questions and Dr. Wright’s answers provide a classic example of Dr. Wright speaking at a level and depth that others may not have thought possible.
Ironically, some people question Dr. Wright’s understanding of technology at the undergraduate level. Not in spite of this, but because of this.
(And it’s questions like this that have dominated the Light Satoshi topic for the past eight years. Frankly, it’s shameful and unfair. It’s something I often force myself to explain to others.)
Anyone who gets the impression that Dr. Wright doesn’t know even the basics should reexamine their basic thinking.
No one should blindly believe anything anyone else says, but a much more common mistake people make about Dr. Wright is to presumptively reject him. It’s time to move on and learn from what happened. From repeated experience in the past, basic prudence would require us to think more carefully and deeply about what Dr. Wright says to avoid embarrassment.
If you really want to investigate the truth about Bitcoin, resist the temptation to focus too much on isolated technologies. It’s a system. More specifically, it is a system that exists in a computational, economic and legal environment.
Your understanding of these issues will largely depend on whether you want a techno-political system primarily for censorship resistance or an economic system primarily for productivity. Each view may have its own respectful basis, but you need to understand the differences before concluding that someone else knows nothing.
I understand both views very well. I just prefer a scalable and productive economic system over a techno-political law-resistance system. There may be room for both systems to exist in the real world. My preferences are related to the values I believe in, and I understand that other people have their own values and beliefs.
So please hear me out on this particular question about Bitcoin’s binary search tree. I discuss this not only because it has unique technical significance, but also because it is a good example of why we should pay attention to what Dr. Wright said.
Merkle Tree and Binary Tree
Dr. Wright said that the Merkle tree structure, originally designed by Satoshi, has now been implemented in BSV along with Simplified Payment Verification (SPV), a binary search tree.
His opponents claim that this is absurdly wrong, since anyone with a basic understanding of computer science will know that Merkle trees are not binary search trees.
His opponents are right in that the Merkle trees in basic applications taught in schools are not binary search trees.
But what they don’t know is that Satoshi designed the Bitcoin Merkle tree to be both a Merkle tree and a search tree, even a binary search tree.
Dr. Wright is once again incredibly right.
I’ll explain the technical details below.
First of all, the core idea of a ‘binary tree’ refers to the ability to cut a tree (containing a collection of data) into two (hence ‘binary’) parts at every step. Based on the match or mismatch, decide which direction to take the next step and discard the half in the opposite direction. This is repeated until the target item is found. This binary approach makes the process very fast and scalable. Because all steps are binary, they progress exponentially, allowing for log scalability.
The fact that you can immediately ignore half the data without risking losing sight of the goal creates this surprising effect. But for this to happen, the nodes and leaves of the tree must be aligned and balanced in a specific way.
Therefore, calling a tree “binary” means that it is structured in such a way that an action (such as a search) can be performed in a binary way. If a structure does not have this binary feature, it is incorrect to call it binary. But if a structure has this binary function, but no one else knows that structure and has never called it binary, then whoever calls it first will be not only correct but also innovative.
Binary trees can be structured to perform a variety of functions and achieve a variety of goals. When a tree is constructed to perform a binary search, it is a binary search tree. However, binary trees can be used for other purposes, such as ensuring data integrity.
So the question is, why does Dr. Wright call Bitcoin’s Merkle tree a binary search tree?
First, if Bitcoin’s Merkle tree is structured in a way to locate specific data and confirm its existence, it is a search tree. No matter what others say, this is clear.
But it’s ‘binary’, so it’s a binary search tree? That’s a more sophisticated consideration.
The answer is yes. Bitcoin’s Merkle tree is a binary search tree because Bitcoin data is intentionally structured as a key-value database. This means that each item (transaction or hash) is associated (labeled) with a key. The keys are sequential. There are several ways to configure keys. This depends on the tree structure and the design of the algorithm (see below for examples). The word ‘key’ here is a standard database description, like a label for an item, and has nothing to do with encryption keys.
This sequential order is natural, as Bitcoin transactions are timestamped according to the time order in which each transaction was received. Now, each sequential key corresponding to a timestamped sequential transaction is embedded, resulting in a sorted and balanced leaf hash tree.
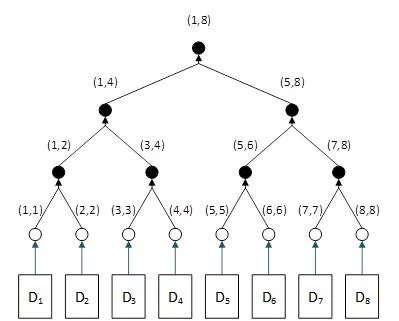
Figure 1 shows an example of a Merkle tree, which is also a binary search tree.
The transaction is denoted Di. Transaction Di corresponds to hash(i, i), which is a special case of key(i, j) with i=j.
Each node is represented by a key consisting of a pair of numbers (i, j), such as (1, 4). The meaning of the numbers is very simple. A node with key (i, j) means that the node’s data and its child nodes contain transactions ranging from i to j. For example, (1, 4) means that the node and its children contain transactions 1, 2, 3, and 4. Implicitly, this also means that transactions 5, 6, 7, and 8 are not relevant. It is included in other branches of (5,8).
According to this sequential numbering, (i, k) and (k+1, j) are two neighboring nodes, as denoted by k and k+1. When two adjacent hashes H(i, k) and H(k+1, j) are concatenated and hashed, a new hash H(i, j) is created. The resulting key (i, j) is expressed as H(i) because concatenating two neighboring hashes concatenates two ranges, i.e. from i to k and k+1 to j, producing a new range i to j, so the resulting hash is denoted as H(i). It’s logical. , Jay). The middle numbers k and k+1 do not appear in the new key (i, j). This is because the range from i to j necessarily means an extended range that includes the middle numbers k and k+1.
Figure 1 shows i=1, 2,… Here is a simple example with 8 people: In reality, i=1, 2,… n. where n is the total number of transactions in the block and can be large.
The Merkle tree is structured as follows:
- Hash each transaction Di to get H(i, i). This is the first level of the Merkle tree where transaction data items and their hashes have a 1:1 correspondence.
- Connect all pairs of adjacent H(i, i) and H(i+1, i+1) to get H(i, i+1). This gets the second level. The second level has n/2 nodes.
- Repeat the same process from step 2 above until you reach the final level with only one node remaining. This is the Merkle route.
Because the number of nodes at each next level is halved, this process quickly reaches the root (top level). Total number of levels m=log2(n). The more transactions there are in a block, the greater the benefit.
For example, if n=8 then m=3. When n=1 million, m=20; When n=1 billion, m=30; When n=1 trillion, m=40, etc. From n=8 to n=1 billion, we can see that the total number of transactions in a block has increased by over 100 million times and the total number of levels in the tree has only increased by a factor of 10.
These are the basic characteristics of Merkle trees. However, it is clear that labeling nodes using sequential keys transforms a Merkle tree into a binary search tree.
The example in Figure 1 assumes that transaction D5 needs to be retrieved. This corresponds to the key (5, 5). We start from the top (root) H(1, 8). This indicates that there are a total of 8 transactions in the block, numbered 1 through 8.
First we compare target (5, 5) with current node (1,8). Since 5 > 8/2, we know the target is on the right. Move to the right to reach node H(5, 8) and ignore the entire left branch, which is half of the tree. If this isn’t clear from this small example, imagine that if there are 1 billion transactions in a block, we skip 500 million transactions in this one step.
Next, we compare target (5, 5) with the current node (5, 8). Since 5=5 we know that we have already got the right part of the key, which is the lower bound of the transaction range. But since 5<8, we move left and reach H(5,5), which corresponds to the D5 transaction, which is the exact transaction we are looking for.
Therefore, the Merkle tree constructed as above is capable of binary search, so it becomes a binary search tree. There’s no debate about this, because this is exactly how a binary search tree is defined.
This binary search tree, combined with the sophisticated design of SPV, makes Bitcoin implemented on BSV very powerful.
Binary Search Tree and SPV
The SPV itself is another topic. Although disclosed in the Bitcoin whitepaper, SPV is only truly understood and developed in Bitcoin SV (BSV). I will skip explaining the SPV itself, but I want to emphasize that it is related to Bitcoin’s binary search tree.
SPV is about scalability. If we only look at the individual case of how SPV works with user submissions of Merkle paths for transactions, it appears to have nothing to do with searches, as Merkle paths are easily created by users. It records not only the transaction ID but also its location, so nothing else can be retrieved from the blockchain. The only thing that remains is that the recipient must compute a Merkle proof to verify the existence of the transaction using the Merkle path.
But remember, SPV is about scalability. This means that it operates on blockchains that have billions or even trillions of transactions in a single block. In these expanded blockchains, scalable and efficient search is absolutely critical. Because otherwise, everyone including sender, receiver and service provider may suffer losses.
Therefore, scalable search with SPV is needed. But what can do this better than a binary search tree?
So binary search tree and SPV work together as if they were holding hands. This is exactly what BSV has done. The upcoming Teranode in testing will feature these features. If you’re not interested in scalable systems, this might not interest you. But that doesn’t mean we should claim ignorance because Dr. Wright claims that the Bitcoin Merkle Tree is a binary search tree. Rather, you should look for your own ignorance in not understanding what he is saying.
View: Bitcoin – Electronic Cash System

Are you new to blockchain? To learn more about blockchain technology, check out CoinGeek’s Blockchain for Beginners section, our ultimate resource guide.